编译技术开发文档
《编译技术》实验开发文档
Author:bush
1 参考编译器介绍
主要参考了教材上PL/0以及tolang
1.1 总体结构
PL/0是一个编译-解释执行程序,总体结构分为两个部分:
- 先把PL/0编译成目标程序(P-code指令)
- 再对目标程序进行解释执行,得到运行结果
1.2 接口设计
PL/0编译程序采用一遍扫描,以语法分析为核心,由它调用词法分析程序取单词,在语法分析过程中同时进行语义分析处理,并生成目标指令。
如遇有语法、语义错误,则随时调用出错处理程序,打印出错信息。
1.3 文件组织
前端和后端分包等。
2 编译器总体设计
2.1 总体结构
总体结构与PL/0不同,是编译程序。
- 先编译成LLVM IR
- 由LLVM IR生成MIPS汇编代码
- 直接运行MIPS汇编代码
编译器总体采用多遍扫描,即先通过一次完整的词法分析得到token序列,再进行语法分析得到语法树。
2.2 接口设计
2.2.1 词法分析器Lexer
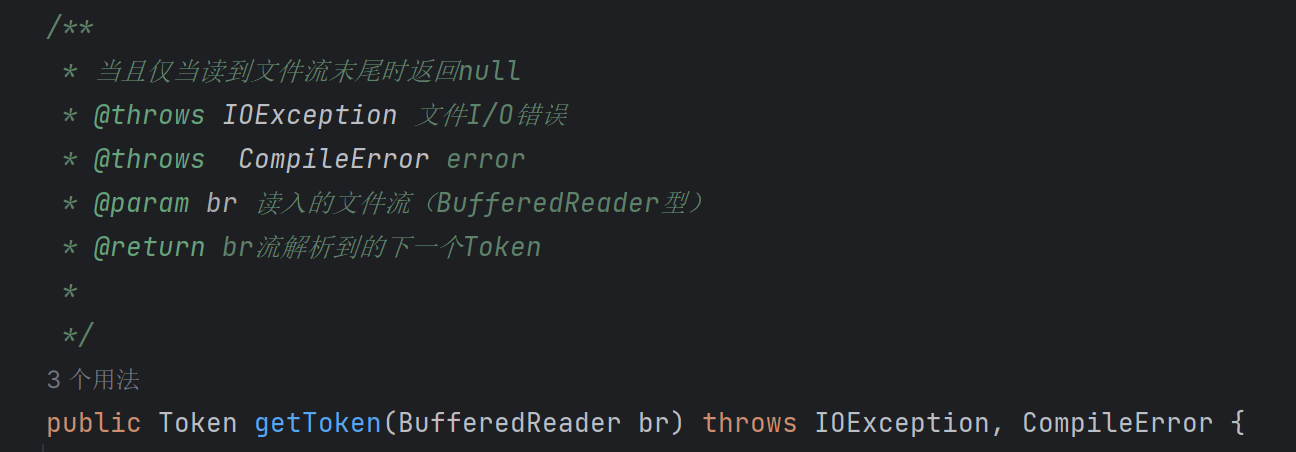
Lexer.java主要提供一个接口getToken()
- 调用形式:
token = lexer.getToken() - 作用:根据设置的读取器
BufferedReader,每次调用返回下一个解析到的Token类符号 - 备注:当且仅当读到文件流末尾时返回
null
2.2.2 语法分析器Parser
Parser.java主要提供一个接口parse()
- 调用形式:
compUnit = parser.parse() - 作用:首先调用词法分析器的接口解析得到token序列,然后递归解析以一个
CompUnit类实例表示的语法树
2.3 文件组织
1 | # 主要文件结构如下 |
3 词法分析设计
3.1 编码前的设计
主要参考的是教材上的PL/0,以及第三章的词法分析示例。
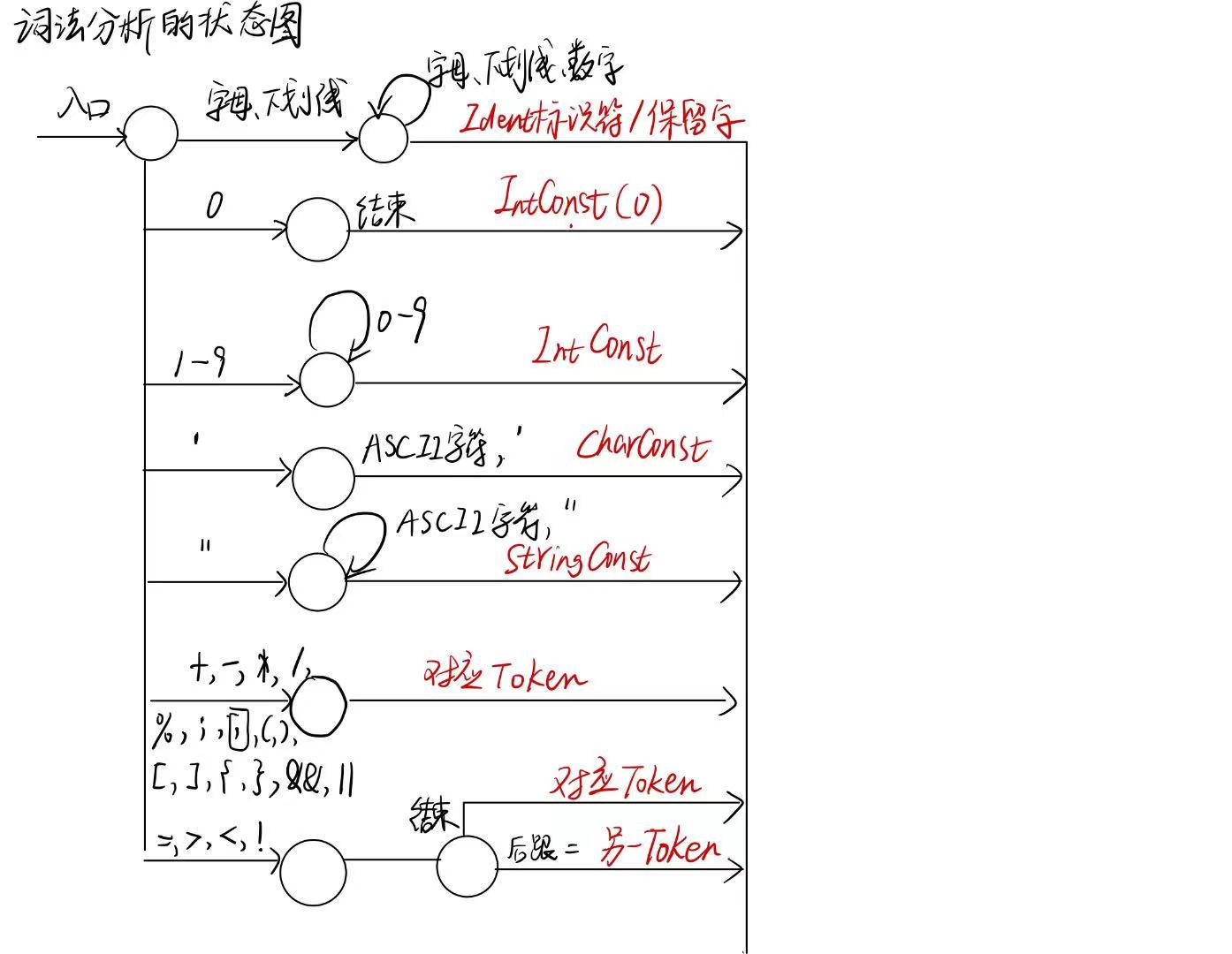
代码大致流程图如上,编码时,主要依靠这张图,其他细节在编码时实现。
Compiler.java这一主程序调用frontedn/Lexer.java中的getSymbol方法。在此次作业中主逻辑还未实现,因此可以在Compiler.java中暂时编写满足本次作业的测试逻辑。
3.2 编码完成后的修改
3.2.1 设计模式的选择、类的设计
- 词法分析器
Lexer.java采用单例模式(饿汉式)的设计模式,作为一个静态类存放到主类Compiler.java中,其方法也多是静态方法,最主要的是getToken方法;
- 单词token作为一个类
Token,类型作为其内部枚举类TokenType; - 编译错误的处理:
CompilerError是一个Exception的子类,在Lexer等各个组件的方法可以被抛出,在主类Compiler中被try-catch处理。
3.2.2 其他更改或BUG
- 最大的疏忽是忘记添加处理注释的代码了,应该把读入
/符号后的逻辑单列出来。 - 另外,只考虑到字符常量中只有一个字符的情况了,没有考虑到转义字符
3.2.3 语法分析完成后的改动
- 最大的改动是,由设计之初的一遍扫描改为多遍扫描
- 在词法分析时,设计采用一遍扫描,即语法分析中每次调用词法分析的接口
getToken()即返回下一个token。
在词法分析程序内部中使用BufferedReader的mark()和reset()两个方法组实现字符读取的回退,在语法分析开始时计划在调用getToken()接口的外层也使用这两个方法实现token的回退和预读。 - 但是这样会使得在接口内部再次调用
mark()覆盖外层的mark()使得无法回退token等问题,因此改为多遍扫描,即在语法分析前先完成整个程序的词法分析得到token序列,接下来的语法分析便不用通过操作读取器回退token,功能完成解耦。
- 在词法分析时,设计采用一遍扫描,即语法分析中每次调用词法分析的接口
- 修改了词法分析解析多行注释的部分:在de完语法分析的bug后,公共测试库全过但测试点16RE,最后发现是词法分析中对多行注释的读取有误
4 语法分析设计
4.1 编码前的设计
- 与词法分析类似,使用单例模式实现
Parser.java - 主要采用递归下降程序实现
- 此外通过预读解决多个规则匹配问题
以下是编写递归程序时的辅助表格,部分非终结符的FIRST略
| 非终结符 | FIRST集 | 完成 |
|---|---|---|
| CompUnit | CONSTTK, INTTK, CHARTK, VOIDTK | V |
| Decl | CONSTTK, INTTK, CHARTK | V |
| FuncDef | VOIDTK, INTTK, CHARTK | V |
| MainFuncDef | INTTK | V |
| ConstDecl | CONSTTK | V |
| VarDecl | INT, CHAR | V |
| FuncType | 'VOIDTK, INTTK, CHARTK | V |
| BType | INTTK, CHARTK | V |
| ConstDef | V | |
| Ident | Vt | V |
| ConstInitVal | V | |
| ConstExp | V | |
| StringConst | Vt | V |
| AddExp | V | |
| MulExp | V | |
| UnaryExp | LPARENT, IDENFR, INTCON, CHRCON, PLUS, MINU, NOT | V |
| PrimaryExp | LPARENT, IDENFR, INTCON, CHRCON | V |
| FuncRParams | V | |
| UnaryOp | PLUS, MINU, NOT | V |
| LVal | IDENFR | V |
| Number | INTCON | V |
| Character | CHRCON | V |
| IntConst | Vt | V |
| CharConst | Vt | V |
| VarDef | V | |
| InitVal | V | |
| Exp | LPARENT, IDENFR, INTCON, CHRCON, PLUS, MINU, NOT | V |
| FuncFParams | INTTK, CHARTK | V |
| FuncFParam | INTTK, CHARTK | V |
| Block | LPARENT | V |
| BlockItem | V | |
| Stmt | V | |
| ForStmt | V | |
| Cond | V | |
| LOrExp | V | |
| LAndExp | V | |
| EqExp | V | |
| RelExp | V |
4.2 编码后的设计
4.2.1 设计模式
- 语法分析器
Parser.java与词法分析器类似,采用饿汉式单例模式; - 单例模式的静态方法与非静态方法的实现效果类似,但为了简便,在语法成分类中要频繁调用的
getSymbol() currentSymbol()等方法设置为静态方法。
4.2.2 递归下降读取逻辑
- 在一个程序要调用一个分析子程序前,需要使用
Parser.getSymbol()读取一个token - 在分析子程序里,分析子程序会递归匹配所有token,但并不会超前读取(例如分析子程序只匹配一个终结符即结束,则不会调用
Parser.getSymbol()),因此一个子成分分析完后,symbol停留在最后匹配到的那个token处 - 接着继续使用
Parser.getSymbol()读取一个token并调用剩下的分析子程序 - 在遇到终结符时,匹配后不需要使用
Parser.getSymbol(),因为递归过程相当于在匹配之前已经执行一次
4.2.3 类设计
-
对于语法树的构建,首先设计了一个语法树节点的接口
SyntaxNode.java:1
2
3
4
5public interface SyntaxNode<T> {
public T parse() throws IOException;
public String outputString();
} -
对于每个语法成分,均设计同名的一个类并实现以上接口;
- 对于该语法成分的一条规则,规则右部语法成分作为该类的一个属性存储
- 若有多条规则,则根据FIRST集的不同划分成不同的子类,超类属性类型为超类,但在
parse()方法中根据当前符号选择实例化不同的子类(方法重写和多态) - 若右部语法成分可重复多次,则存储对应的列表
- 若右部语法成分可选,则值非
null时表示存在,否则不存在
- 若有多条规则,则根据FIRST集的不同划分成不同的子类,超类属性类型为超类,但在
- 类的
parse()方法会根据语法分析器当前解析到的符号Parser.currentSymbol()向前解析,并返回自身(return this) - 顶层语法成分调用
parse()方法解析时,为下层语法成分属性赋值一个调用过自身parse()方法的new对象,这样就实现了递归 - 每个语法成分的
outputString()方法按照同样的递归逻辑返回需要输出的内容和格式
- 对于该语法成分的一条规则,规则右部语法成分作为该类的一个属性存储
-
为了使得结构清晰,按功能将语法成分包为
declaration,expression,function,statement,terminal五个包 -
对于有多条规则的语法成分的子类也分包管理,如
stmts,unaryexps,primaryexps
4.2.4 FIRST集冲突解决方案
- 若FIRST集冲突,可以类似的查看规则的SECOND集,并使用
preReadNext()预读一个token的方法区分(大部分可以解决) - 仅在
CompUnit->Decl|FuncDef,SECOND集仍冲突,则preReadNextNext()预读下下个token可以区分 - 仅在
Stmt的推导时,使用SECOND集仍然难以区分,此处采用回溯token的方法解决- 在回溯时需要同时回溯抛出的错误!不然会出现多输出错误的情况
4.2.5 左递归文法解决方案
-
对于左递归文法,将规则改写为扩充的BNF范式。
以MulExp → UnaryExp | MulExp ('*' | '/' | '%') UnaryExp这条规则为例,消除左递归后得到
MulExp → UnaryExp { ('*' | '/' | '%') UnaryExp } -
以这条规则为例,这些具有递归文法的类属性设置为一个
UnaryExp类和一个元素为OpUnaryExp类的列表分别表示EBNF范式的两部分 -
其中
OpUnaryExp为静态内部类,相当于一个二元组,包含每个重复的符号op和unaryExp -
至此便消除左递归文法,在分析方法中不会递归调用自己,而是不断调用下一层的语法成分分析方法;并且在输出方法
outputString()中,也可以通过类似逻辑输出正确的语法树结构 -
从
UnaryExp->MulExp->AddExp->RelExp->EqExp->LAndExp->LorExp各层次间关系是一模一样的,因此编写完UnaryExp->MulExp后,可通过代码查找替换迁移得到后面的层间关系;手稿如下:
4.2.6 关于错误处理的修改
-
在之前的词法分析设计时,设计了一个自定义的
CompileError并继承Exception类,错误通过throw抛出自CompileError报错并在上层处理,但在此次编码时发现:- 语法分析与词法分析不同,词法分析是顺序执行,可以使用throw抛出异常,在顶层记录错误并继续执行
- 而语法分析是递归调用的,不能够被中断,因此把错误暂存而不是抛出
-
并且由一遍扫描改为多遍扫描也不能顺序地依次处理错误。因此,修改处理逻辑,将所有错误先暂存并直接处理,最后一起输出。
-
需要注意的是一遍扫描错误抛出的顺序是按行数升序的,但多遍扫描的顺序一次是词法分析错误、语法分析错误、语义分析错误等,需要在输出前按行数排序再输出
5 语义分析设计
5.1 编码前的设计
在这一阶段,不需要进行中间代码生成,只需要输出符号表内容。且指导书在中间代码生成这一章写道:
对于符号表的生命周期,可以是遍历 AST 后,生成一张完整的符号表,然后再进行代码生成;也可以是在遍历过程中创建栈式符号表,随着遍历过程创建和销毁,同时进行代码生成。
因此,暂时设计为先遍历AST生成树形符号表,再在后面的中间代码生成时做增量式开发。
采用访问者模式:
- 设计一个单例
Visitor类,其包含不同语法成分的visit()方法,解析语法树并调用下层的visit()方法。 - 仅
visit(CompUnit compUnit)方法为public以便外层调用,其余语法成分的visit()方法设置为private被其调用。
5.2 编码后的设计
5.2.1 符号和符号表的类设计
-
符号类
Symbol设置为抽象类:ConstInt, ConstChar, ConstIntArray, ConstCharArray, ConstInt, ConstChar, ConstIntArray, ConstCharArray这8种符号每种各设置一个子类xxxSymbol继承Symbol;IntFunc, CharFunc, VoidFunc这3种符号设计一个子类FuncSymbol;共9个继承。 -
符号表需要维持树状结构,因此添加
fatherTable这一属性。构造方法如下:1
2
3
4
5
6
7
8
9public SymbolTable(SymbolTable fatherTable) {
this.fatherTable = fatherTable;
this.scopeId = scopeIdCounter++;
fatherTable.childrenTables.add(this);
}
private SymbolTable() {
this.fatherTable = null;
this.scopeId = scopeIdCounter++;
}其中根符号表作为静态属性存储以便输出:
1
public static final SymbolTable ROOT = new SymbolTable(); // 根符号表,即全局符号表
5.2.2 访问者设计
- 访问者总体结构与 #5.1 编码前的设计相同;
- 在访问者中维护一个
curSymbolTab属性保存当前的符号表; - 另有其他属性用来辅助语义分析(直接作为Visitor属性就不用在方法中传递参数了)。
5.2.3 语义分析后的改动
- 解耦词法分析器和语法分析器,优化了对外接口
- 为语法成分属性添加Getter
- UnaryExp → UnaryOp UnaryExp这条规则不应拆分子类而应把UnaryOp作为UnaryExp的属性
- 重构多条规则语法成分:将Stmt、BlockItem、PrimaryExp中的自反属性删去;将UnaryExp中的属性更名为UnaryExpWithoutOp。这样避免了在语义分析时,使用
unaryExp.getUnaryExp(), primaryExp.getPrimaryExp(), stmt.getStmt() instanceof ReturnStmt等等冗余且易出错的调用。
5.2.4 完成后的思考
相比于语法分析,这次的主要代码均在一个文件下(Visitor.java),耦合度高、模块化差、难以阅读和调试。但由于这次只是部分的语义分析,不涉及中间代码生成,因此期待在后面的迭代中优化结构、解耦合。
6 代码生成设计
6.1 编码前的设计
6.1.1 中间代码生成设计
按照教程的构建单元设置相关类:
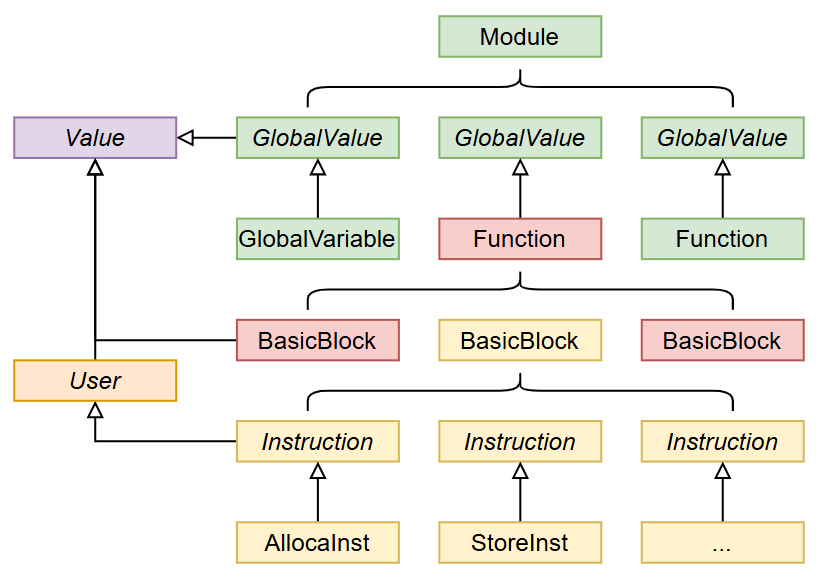
类里均存放初始化的值,仅仅用于转成LLVM IR文本。实际要输出常量的值应差符号表。
指令:
| LLVM IR | 使用方法 | 简介 |
|---|---|---|
add |
<result> = add <ty> <op1>, <op2> |
/ |
sub |
<result> = sub <ty> <op1>, <op2> |
/ |
mul |
<result> = mul <ty> <op1>, <op2> |
/ |
sdiv |
<result> = sdiv <ty> <op1>, <op2> |
有符号除法 |
srem |
<result> = srem <baseType> <op1>, <op2> |
有符号取余 |
icmp |
<result> = icmp <cond> <ty> <op1>, <op2> |
比较指令 |
and |
<result> = and <ty> <op1>, <op2> |
按位与 |
or |
<result> = or <ty> <op1>, <op2> |
按位或 |
call |
<result> = call [ret attrs] <ty> <name>(<...args>) |
函数调用 |
alloca |
<result> = alloca <baseType> |
分配内存 |
load |
<result> = load <ty>, ptr <pointer> |
读取内存 |
store |
store <ty> <initValue>, ptr <pointer> |
写内存 |
getelementptr |
<result> = getelementptr <ty>, ptr <ptrval>{, <ty> <idx>}* |
计算目标元素的位置(数组部分会单独详细说明) |
phi |
<result> = phi [fast-math-flags] <ty> [<val0>, <label0>], ... |
/ |
zext..to |
<result> = zext <ty> <initValue> to <ty2> |
将 ty 的 initValue 的 baseType 扩充为 ty2(zero extend) |
trunc..to |
<result> = trunc <ty> <initValue> to <ty2> |
将 ty 的 initValue 的 baseType 缩减为 ty2(truncate) |
br |
br i1 <cond>, label <iftrue>, label <iffalse> br label <dest> |
改变控制流 |
ret |
ret <baseType> <initValue> , ret void |
退出当前函数,并返回值 |
- 在生成对应指令时,将slot加入函数域。例如在
visitAddExp中,仅在在生成add指令时将result作为新slot加入函数域,其他slot均在调用的visitMulExp中已加入函数域。 - 符号类中新增address字段,存放符号分配到的地址空间
- 我们规定数组名只用来(1)函数传参(此时应由FuncRParam一路推导至Ident,不存在任何其他符号),(2)通过索引取数组里面的值。
| 全局作用域 | 局部作用域 | 共性 | |
|---|---|---|---|
| 常量 | 单个常量和常量数组均需给定ConstExp(即可在编译时计算的)初始值 |
||
| 变量 | 若有初始值,则必须是可计算的ConstExp;若无初始值,置零 |
可以是不可计算的Exp |
可以不带初始值 |
| 共性 | @声明,在顶层,属于GlobalValue;需要保存初始值 |
常量和变量junalloca指令声明,仅保存对应的虚拟寄存器 |
-
一个if语句将当前基本块分为4个基本块(有else)或3个基本块(无else)
-
一个for语句将当前基本块分为5块
B1 preForStmt(若无preForStmt,则无B1) B2 Cond,条件跳转指令B3、B5(若无Cond,则是无条件跳转B3) B3 Stmt,无条件跳转B4 B4 postStmt,无条件跳转B2 (continue语句跳点) B5 (end)(break语句跳点) -
暂时不考虑SSA形式和phi指令,符号表存储地址,每次引用变量使用load,赋值变量使用store。
-
函数传递的非指针参数不能修改,因此在进入函数时,需要为其alloca一个地址空间,并将传进的参数赋给它(相当于变量定义)。不能在第一次使用时再分配并赋值,因为如果在循环体内使用该变量,则会导致死循环:
1 | int fun2(int a) // a=6 |
1 | define dso_local i32 @fun2(i32 %0) { |
6.1.2 后端代码生成设计
-
以函数为单位管理栈帧、分配全局寄存器,以基本块为单位分配临时寄存器(寄存器分配实现在文档的优化部分)
-
在LLVM IR中,存在i32和i8两种类型,但是在MIPS中,均使用32位字存储。
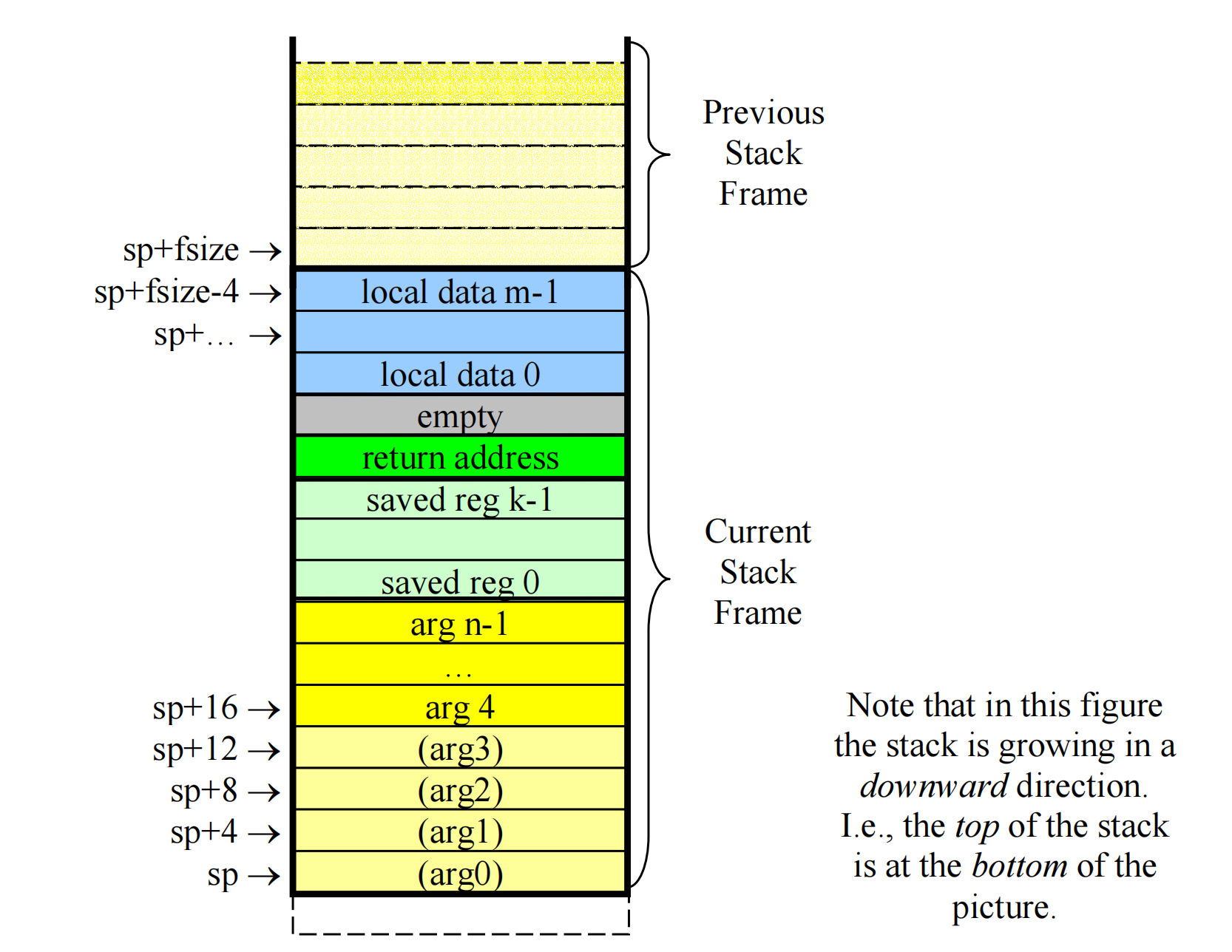
-
栈帧结构(简化了部分结构)
1
2
3
4
5
6
7
8
9
10
11
12/**
* 栈帧结构(从高到低增长):
* sp+size->|- - - - - - - | 以下为栈帧内容:
* | 局部变量 |
* |- - - - - - - | 以下调用函数后需生成的:
* | 返回地址 |
* |- - - - - - - |
* | (保留寄存器) | (即全局寄存器s0-s7)
* |- - - - - - - |
* | 被调用者参数 | (包括a0-a3。从高到低,先压最后一个参数)
* sp-> |- - - - - - - |
*/
-
函数调用设计:
1
2
3
4
5
6
7
8
9
10
11
12
13
14* 【调用者动作】:
* 1. 保存ra寄存器
* 2. 将后续需要用到的保留寄存器值存入栈中
* 3. 将参数压栈、[如果a0-a3有冲突(需要传递且后续要用到),则需要保存并恢复]
* 4. 更改sp寄存器的值
* 5. 使用jal指令
* 6. 取v0返回值并填入相应寄存器(若有返回值)
* 7. 将sp寄存器的值恢复
* 8. 恢复ra寄存器值、保存的寄存器值、恢复冲突的a0-a3寄存器值
* 9. 继续其他指令……
* 【被调用者动作】:
* 1. 执行函数逻辑,若使用参数则取寄存器值或栈上值
* 2. 执行到ret指令,返回值存入v0(若有)
* 3. 使用jr ra返回- 需要注意的是,由于被调用者需要靠偏移取参数,所以在将参数压栈时,应该保证不会出现寄存器溢出的情况,否则会导致偏移与参数不对应。
6.2 编码后的设计
- 遵循里氏替换原则和开放封闭原则,将LLVM IR和MIPS的指令都设置为一个接口或抽象类,并在具体的每条指令中重写对应的输出方法,调用者使用指令类的多态属性完成每条指令的输出。且当需要新增指令时,不需要修改原来的代码,只需要新增类并继承抽象父类或实现接口即可。
7. 代码优化设计
7.1. 寄存器分配
在目标代码生成的指导书中:
在 MIPS 这种寄存器到寄存器模型中,每个参与运算的值都必须被加载到寄存器中,因此在我们的 IR 中,参与运算的变量都应该对应一个寄存器,在 IR 中,我们将其称为虚拟寄存器。虚拟寄存器数目是无限的,但是当翻译为目标平台的汇编代码时,就需要将其映射到一组有限的寄存器中,这个过程就是寄存器分配。
对于规范的寄存器分配,则需要考虑全局寄存器和局部寄存器的分配,分别对应 MIPS 中的
s和t寄存器。……
因此,我在生成目标代码时就已经分配了寄存器(因此优化前和优化后finalCycle差距可能不大)。以下是具体实现思路。
7.1.1 跨块活跃变量:采用图着色法分配全局寄存器
7.1.1.1 数据流分析
在LLVM IR每条具体指令类中添加def和use集,并在构造方法中将对应变量加入这两个集合。
1 | // 当有集合的in集发生变化时,继续迭代 |
在对每条指令的liveIn和liveOut集计算的基础上,计算基本块的liveIn和liveOut集。
需要注意在计算函数的跨块活跃变量时,将所有的liveIn和liveOut集变量加入后,需要删除所有作为函数参数的变量(包括指针型)。
这是因为函数参数一概不分配寄存器,因此尽管在参数中出现,也不加入跨块活跃变量集合。
7.1.1.2 图着色算法
为了简便,我在实现中对冲突的定义是:活跃范围重合。因此,在数据流分析后,同时出现在liveIn或liveOut集合的、以及在块内活跃范围冲突的变量视为冲突。
1 | // 构造冲突图 |
其中保存冲突图的副本是为了在后续移走节点也能查询到每个变量的冲突情况。
1 | LinkedList<Slot> queue = new LinkedList<>(); |
这里对于选择哪个节点移除暂时没有实现选择算法,后续可能优化为引用次数最少的不分配全局寄存器。
需要注意由于HashMap遍历顺序的不确定性,需要先将其排序再进行后续操作。
7.1.2 不跨块活跃的变量:采用寄存器池分配临时寄存器
在后端实现了一个RegisterPool.java类,虽然全局寄存器不使用寄存器池分配,但是实现这个类可以便于对变量对应的寄存器统一管理。生成目标代码时,可以统一使用提供的接口找到对应的寄存器。
总的来说,我实现的临时寄存器池使用FIFO算法,维护一个allocated表和tempQueue,前者存储变量对应的寄存器,后者是一个记录分配顺序的队列。当新增变量时,从寄存器池中分配一个变量,并添加allocated表项、加入tempQueue队尾;当释放寄存器时,移除allocated表项以及tempQueue对应寄存器;当寄存器不够需要溢出时,取tempQueue的队首溢出到内存并分配。
1 | /** |
因此,每条指令的翻译步骤即:
- 使用 find 获取 use 的寄存器
- 使用 deallocUse 回收 use 中不活跃变量的寄存器
- 使用 allocDef 分配 def 使用的寄存器【allocDef可能返回null,此时需要保存到栈上】
- 使用 allocTemp 分配不绑定slot的寄存器
- 生成MIPS指令
这些步骤不能随意调换顺序。具体来说:
- 先
find再deallocUse(否则找不到就释放了) - 先
deallocUse再allocDef(这样可以立即使用use不再使用的寄存器,例如addiu $t0, $t0, -4这种指令) - 先
allocDef再allocTemp。(否则,因为后者不绑定Slot,会分配到一样的寄存器而出错)
此优化与MIPS生成一起完成,因此提交的优化前目标代码与此一致。
7.2. 基本块合并
例如,在公开testcase7中,生成了如下代码:
1 | 101: ; preds = 96 |
经过基本块合并优化后:
1 | 101: ; preds = 96 |
7.3. 乘除法优化
只针对第二个操作数为立即数的乘除指令进行优化。
7.3.1 乘法优化
对于乘数为0、1、2的整数幂、2的整数幂的相反数、2的整数幂-1、2的整数幂-2、2的整数幂+1进行优化,转为若干移位指令和加减指令。
7.3.2 除法优化
对于除数为2的整数幂、2的整数幂的相反数进行优化。
此外,对于能转化为乘法和移位运算的进行优化,例如对于testcase7中:
1 | div $t0, $t0, 5 |
被优化为:
1 | slt $t1, $zero, $t0 |
需要注意,优化时,需要分正负两种情况,不然会产生错误。
其他说明
由于生成MIPS时直接完成寄存器分配这一“优化任务”,因此耗费了许多时间。最后因时间紧迫,其他优化暂时没有完成。
Author:bush
更新日志:
- 2024.9.24:完成词法分析,完成文档#1、#2、#3
- 2024.10.14:完成语法分析及此部分文档#4,修改#2.2,新增#3.2.3
- 2024.10.19:在期中模拟考发现回溯时未回溯已抛出错误导致多输出错误,修改#4.2.5
- 2024.11.2:完成语义分析,完成文档#5
- 2024.12.12:完成MIPS代码生成,完成文档#6
- 2024.12.17:完成优化文档#7