操作系统复习笔记2-内存管理
此部分内容为笔者大二下学期的复习笔记摘过来的。
Ⅱ内存管理
一、内存管理基础
单道程序的内存管理
- 在单道程序环境下,整个内存里只有两个程序:一个 用户程序和操作系统。 §操作系统所占的空间是固定的。 §因此可以将用户程序永远加载到同一个地址,即用户 程序永远从同一个地方开始运行。 §用户程序的地址在运行之前可以计算。
- 优点:执行过程中无需地址翻译,程序运行速度快。
- 缺点: §比物理内存大的程序无法加载,因而无法运行。 §造成资源浪费(小程序会造成空间浪费;I/O时间长 会造成计算资源浪费)。
多道程序的内存管理
空间的分配:分区式分配
把内存分为一些大小相等或不等的分区(partition) ,每个应用程序占用一个或几个分区。操作系统 占用其中一个分区。
适用于多道程序系统和分时系统,支持多个程序 并发执行,但难以进行内存分区的共享。
固定式分区
- 把内存划分为若干个固定大小的连续分区
- 分区大小相等:只适合于多个相同程序的并发执行(处 理多个类型相同的对象)。
- 优点:易于实现,开销小。
- 缺点:内碎片造成浪费,分区总数固定,限制了 并发执行的程序数目。
- 采用的数据结构:分区表--记录分区的大小和 使用情况。
单一队列的分配方式
- 当需要加载程序时,选择一个当前闲置且容量足够大 的分区进行加载,可采用共享队列的固定分区(多个 用户程序排在一个共同的队列里面等待分区)分配。
多队列分配方式
- 由于程序大小和分区大小不一定匹配,有可能形成一 个小程序占用一个大分区的情况,从而造成内存里虽 然有小分区闲置但无法加载大程序的情况。这时,可 以采用多个队列,给每个分区一个队列,程序按照所 需内存的大小排在相应的队列里。
固定式分区的管理
固定式分区(静态存储区域):当系统初始化时,把存储 空间划分成若干个任意大小的区域;然后,把这些区域分 配给每个用户作业。
可变式分区
- 可变式分区:分区的边界可以移动,即分区的大 小可变。
- 优点:没有内碎片。
- 缺点:有外碎片。
闲置空间的管理
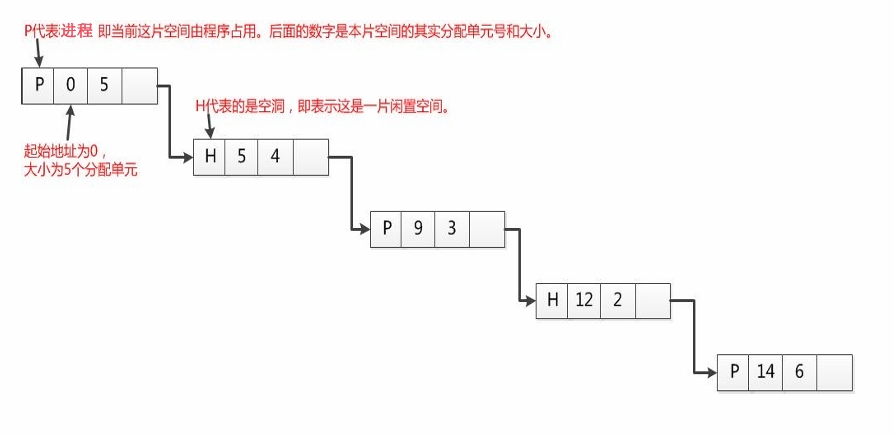
在管理内存时,OS需要知道内存空间有多少空闲。这 就必须跟踪内存的使用,跟踪的办法有两种:位图表 示法(分区表)和链表表示法(分区链表)
位图表示法
- 给每个分配单元赋予一个二进制数位,用来记录该分 配单元是否闲置。
- 例如:数位取值为0表示单元闲置,取值为1则表示已 被占用。

链表表示法
- 将分配单元按照是否闲置链接起来,这种方法称为链 表表示法
两种方法的特点
- 位图表示法:
- 空间开销固定:不依赖于内存中的程序数量。
- 时间开销低:操作简单,直接修改其位图值即可。
- 没有容错能力:如果一个分配单元对应的标志位为1,不能确定是否因错 误变成1。
- 链表表示法:
- 空间开销:取决于程序的数量。
- 时间开销:链表扫描速度较慢,还要进行链表项的插入、删除和修改。
- 有一定容错能力:因为链表有被占空间和闲置空间的表项,可相互验证。
可变分区的管理(以DOS为例)
- 采用两张表:已分配分区表和未分配分区表。
- 每张表的表项为存储控制块MCB(Memory Control Block),包括AMCB(Allocated MCB)和FMCB(Free MCB)
- 空闲分区控制块按某种次序构成FMCB链表结构。当分 区被分配出去以后,前、后向指针无意义。
分区分配操作
分配内存
- 事先规定:当剩余空闲分区≤ size时,不再进一步 分割。
- 设请求的分区大小为u.size,空闲分区的大小为 m.size。
- 若m.size-u.size≤size,将整个分区分配给请求者 。
- 否则,从该分区中按请求的大小划分出一块内存空间 分配出去,余下的部分仍留在空闲分区表/链中。
回收内存
- 待回收分区与前一个空闲分区邻接:合并后首地 址为空闲分区的首地址,大小为二者之和。
- 待回收分区与后一个空闲分区邻接:合并后首地 址为回收分区的首地址,大小为二者之和。
- 待回收分区与前后两个空闲分区邻接:合并后首 地址为前一个空闲分区的首地址,大小为三者之 和。
- 待回收分区不与空闲分区邻接:在空闲分区表中 新建一表项,并填写分区大小等信息。
基于顺序搜索的分配算法
- 首次适应算法(First Fit):每个空闲区按其 在存储空间中地址递增的顺序连在一起,在为作 业分配存储区域时,从这个空闲区域链的始端开 始查找,选择第一个足以满足请求的空白块。
- 下次适应算法(Next Fit):把存储空间中空闲 区构成一个循环链表,每次为存储请求查找合适 的分区时,总是从上次查找结束的地方开始,只 要找到一个足够大的空闲区,就将它划分后分配 出去。
- 最佳适应算法(Best Fit):为一个作业选择分 区时,总是寻找其大小最接近于作业所要求的存 储区域。
- 最坏适应算法(Worst Fit):为作业选择存储 区域时,总是寻找最大的空闲区。
算法特点
- 首次适应:优先利用内存低地址部分的空闲分区。但由于 低地址部分不断被划分,留下许多难以利用的很小的空闲 分区(碎片或零头),而每次查找又都是从低地址部分 开始,增加了查找可用空闲分区的开销。
- 下次适应:使存储空间的利用更加均衡,不致使小的空闲 区集中在存储区的一端,但这会导致缺乏大的空闲分区。
- 最佳适应:若存在与作业大小一致的空闲分区,则它 必然被选中,若不存在与作业大小一致的空闲分区, 则只分配比作业稍大的空闲分区,从而保留了大的空 闲分区。最佳适应算法往往使剩下的空闲区非常小, 从而在留下许多难以利用的小空闲区(碎片)。
- 最坏适应:总是挑选满足作业要求的最大的分区分配 给作业。这样使分给作业后剩下的空闲分区也较大, 可装下其它作业。由于最大的空闲分区总是因首先分 配而划分,当有大作业到来时,其存储空间的申请往 往会得不到满足。
基于索引搜索的分配算法
基于顺序搜索的动态分区分配算法一般只是适合于较 小的系统,如果系统的分区很多,空闲分区表(链) 可能很大(很长),检索速度会比较慢。为了提高 搜索空闲分区的速度,大中型系统采用了基于索引搜 索的动态分区分配算法。
(1)快速适应算法
快速适应算法,又称为分类搜索法,把空闲分区按容量大小进行分类,常用大小的空闲区设立单独的空闲 区链表。系统为多个空闲链表设立一张管理索引表。
- 优点:
- 查找效率高,仅需要根据程序的长度,寻找到能容纳它的最小空闲区链表 ,取下第一块进行分配即可。 该算法在分配时,不会对任何分区产生分割,所以能保留大的分区,也不 会产生内存碎片。
- 缺点:
- 分区回收算法复杂(链表的插入、分区合并等),系统开销较大。在分配 空闲分区时是以进程为单位,一个分区只属于一个进程,存在一定的浪费 。(空间换时间)
(2)伙伴系统
- 固定分区方式不够灵活,当进程大小与空闲分区大小 不匹配时,内存空间利用率很低。
- 动态分区方式算法复杂,回收空闲分区时需要进行分 区合并等,系统开销较大。
- 伙伴系统(buddy system)是介于固定分区与可变分 区之间的动态分区技术。
- 伙伴:在分配存储块时将一个大的存储块分裂成两个大小相等的小块,这两个小块就称为“伙伴”。
Linux采用伙伴系统。
系统中的碎片
- 内存中无法被利用的存储空间称为碎片。
内碎片
- 指分配给作业的存储空间中未被利用的部分,如固定 分区中存在的碎片。
- 单一连续区存储管理、固定分区存储管理等都会出现 内部碎片。
- 内部碎片无法被整理,但作业完成后会得到释放。它 们其实已经被分配出去了,只是没有被利用。
外碎片
- 指系统中无法利用的小的空闲分区。如分区与分区之 间存在的碎片。这些不连续的区间就是外部碎片。动 态分区管理会产生外部碎片。
- 外部碎片才是造成内存系统性能下降的主要原因。外 部碎片可以被整理后清除。
- 消除外部碎片的方法:紧凑技术。
紧凑技术(Compaction)
- 通过移动作业,把多个分散的小分区拼接成一个 大分区的方法称为紧凑(拼接或紧缩)。
- 目标:消除外部碎片,使本来分散的多个小空闲 分区连成一个大的空闲区。
- 紧凑时机:找不到足够大的空闲分区且总空闲分 区容量可以满足作业要求时。
实现支撑 - 动态重定位:作业 在内存中的位置发 生了变化,这就必 须对其地址加以修 改或变换。
基于紧凑技术的动态分区技术
多重内存分配
多重分区分配:为了支持结构化程序设计,操作系 统往往把一道作业分成若干片段(如子程序、主 程序、数据组等)。这样,片段之间就不需要连 续了。只要增加一些重定位寄存器,就可以有效 地控制一道作业片段之间的调用。
分区的存储保护
存储保护是为了防止一个作业有意或无意地破坏操作系 统或其它作业。常用的存储保护方法有
- 界限寄存器方法:
- 上下界寄存器方法
- 基址、限长寄存器(BR,LR) 方法
- 存储保护键方法:
- 给每个存储块分配一个单独的保护键,它相当于一把锁。
- 进入系统的每个作业也赋予一个保护键,它相当于一把钥匙。
- 当作业运行时,检查钥匙和锁是否匹配,如果不匹配,则系统发出保护性 中断信号,停止作业运行。
覆盖和交换
- 覆盖与交换技术是在多道程序环境下用来扩充内 存的两种方法。
- 覆盖与交换可以解决在小的内存空间运行大作业 的问题,是“扩充”内存容量和提高内存利用率 的有效措施。
- 覆盖技术主要用在早期的OS 中,交换技术则用 在现代OS中
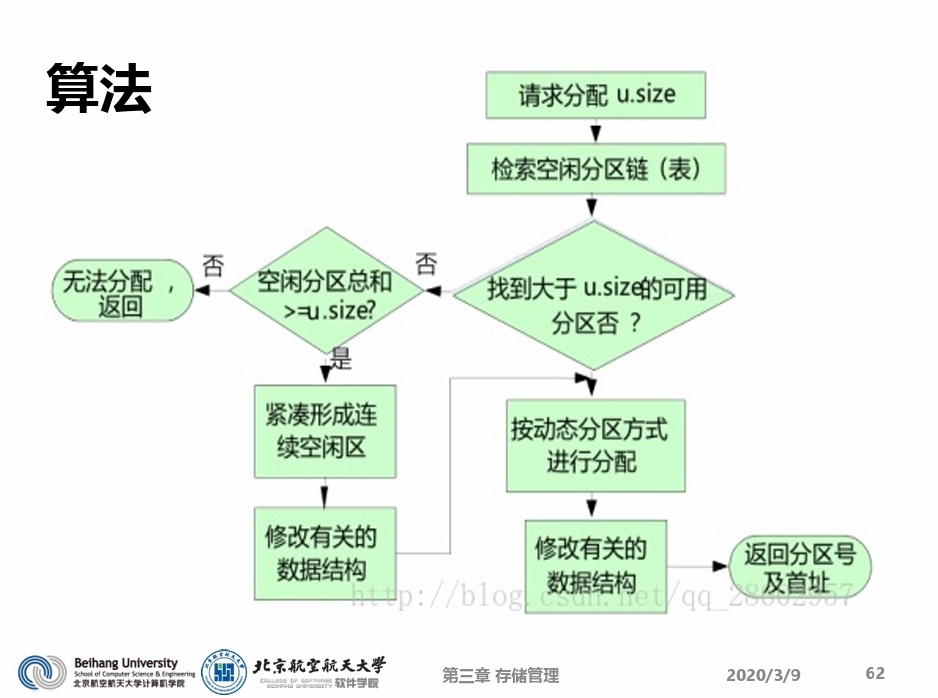
覆盖(Overlay)
- 覆盖:把一个程序划分为一系列功能相对独立的 程序段,让执行时不要求同时装入内存的程序段 组成一组(称为覆盖段),共享主存的同一个区 域,这种内存扩充技术就是覆盖。
- 主要用在早期的OS 中(内存<64KB),可用的 存储空间受限,某些大作业不能一次全部装入内 存,产生了大作业与小内存的矛盾。
- 程序段先保存在磁盘上,当有关程序段的前一部 分执行结束,把后续程序段调入内存,覆盖前面 的程序段(内存“扩大”了)。
- 一般要求作业各模块之间有明确的调用结构,程序员向系统指明覆盖结构,然后由os完成自动覆 盖。
交换(Swapping)
- 交换:把暂时不用的某个(或某些)程序及其数 据的部分或全部从主存移到辅存中去,以便腾出 存储空间;接着把指定程序或数据从辅存读到相 应的主存中,并将控制转给它,让其在系统上运 行。
- 优点:增加并发运行的程序数目,并且给用户提 供适当的响应时间;编写程序时不影响程序结构
- 缺点:对换入和换出的控制增加处理机开销;程 序整个地址空间都进行传送,没有考虑执行过程 中地址访问的统计特性。

交换技术的几个问题
- 选择原则,即将哪个进程换出内存?
- 等待I/O的进程
- 交换时机的确定,何时需发生交换?
- 只要不用就换出(很少再用)
- 只在内存空间不够或有不够的危险时换出
- 交换时需要做哪些工作?
- 保存前一个进程的运行现场:寄存器、堆栈等
- 创建新进程的运行现场
- 换入回内存时位置的确定
覆盖与交换技术的区别
- 覆盖可减少一个程序运行所需的空间。交换可让 整个程序暂存于外存中,让出内存空间。
- 覆盖是由程序员实现的,操作系统根据程序员提 供的覆盖结构来完成程序段之间的覆盖。交换技 术不要求程序员给出程序段之间的覆盖结构。
- 覆盖技术主要对同一个作业或程序进行。交换主 要在作业或程序间之间进行。
二、页式内存管理
补充知识:程序、进程和作业
- 程序是静止的,是存放在磁盘上的可执行文件
- 进程是动态的。进程包括程序和程序处理对象( 数据集),是一个程序的执行过程,是分配资源 的基本单位。通常把进程分为系统进程和用户进 程:
- 系统进程:完成操作系统功能的进程;
- 用户进程:完成用户功能的进程。
- 作业是用户需要计算机完成的某项任务,是要求 计算机所做工作的集合。
作业、进程和程序之间的联系
- 作业通常包括程序、数据和操作说明书3部分。
- 每一个进程由进程控制块PCB、程序和数据集合组 成。这说明程序是进程的一部分,是进程的实体 。
- 因此,一个作业可划分为若干个进程来完成,而 每一个进程有其实体——程序和数据集合。
分页式存储管理的基本思想
- 基本思想:把一个逻辑地址连续的程序分散存放到若 干不连续的内存区域内,并保证程序的正确执行。
- 带来的好处:既可充分利用内存空间,又可减少移动 带来的开销
纯分页系统
- 不具备页面对换功能的分页存储管理方式,不支持虚 拟存储器功能,这种存储管理方式称为纯分页或基本分页存储管理方式。(v.s.请求分页)
- 在调度一个作业时,必须把它的所有页一次装到主存 的页框内;如果当时页框数不足,则该作业必须等待 ,系统再调度另外作业。
- 优点:
- 没有外碎片,每个内碎片不超过页大小
- 一个程序不必连续存放
- 便于改变程序占用空间的大小
- 缺点:
- 程序全部装入内存;有内碎片
基本概念
- 页:把每个作业的地址空间分成一些大小相等的片, 称之为页面(Page)或页,各页从0开始编号。
- 存储块:把物理内存的存储空间也分成与页面相同大 小的片,这些片称为存储块,或称为页框(Frame) ,同样从0开始编号。
- 页表:为便于在内存找到进程的每个页面所对应的页 框,分页系统中为每个进程配置一张页表。进程逻辑 地址空间的每一页,在页表中都对应有一个页表项。
页面的大小
- 页大小(与块大小一样)是由硬件来决定的,通常为2的 幂
- 选择页的大小为2的幂可以方便地将逻辑地址转换为页框 号和页偏移。
- 如果逻辑地址空间为2^m,且页大小为2^n单元,那么逻辑地址的高m-n位表示页号 (页表的索引),而低n位表示页偏移。
- 每页大小从512B到16MB不等。
- 现代操作系统中,最常用的页面大小为4KB。
若页面较小
- 减少页内碎片和总的内存碎片,有利于提高内存利用率。
- 每个进程页面数增多,使页表长度增加,占用内存较大。
- 页面换进换出速度将降低。
若页面较大
- 增加页内碎片,不利于提高内存利用率。
- 每个进程页面数减少,页表长度减少,占用内存较小。
- 页面换进换出速度将提高。
关于页表
- 页表存放在内存中,属于进程的现场信息。
- 用途:
- 记录进程的内存分配情况
- 实现进程运行时的动态重定位。
- 访问一个数据需访问内存2 次(页表一次,内存 一次)。
- 页表的基址及长度由页表寄存
一级页表的问题
- 若逻辑地址空间很大(2^32 ∼2^64 ) ,则划分的页 比较多,页表就很大,占用的存储空间大(要求连续 ),实现较困难。
- 例如,对于32 位逻辑地址空间的分页系统,如果规 定页面大小为4 KB 即2^12 B,则在每个进程页表 就由高达2^20 页表项组成。设每个页表项占用4个字 节,每个进程仅仅页表就要占用4 MB 的内存空间。
- 解决问题的方法:多级页表
- 页表分级管理
- 动态调入页表: 只将当前需用的部分页表项调入内存,其余的需用时再调 入
二级页表
- 将页表再进行分页,离散地将各个页表页面存放在不 同的物理块中,同时也再建立一个外层页表用以记录 页表页面对应的物理块号。
- 正在运行的进程先把外层页表(页表的页表)调入内 存,而后动态调入内层页表。只将当前所需的一些内 层页表装入内存,其余部分根据需要再陆续调入。
多级页表
多级页表结构中,指令所给出的地址除偏移地址 之外的各部分全是各级页表的页表号或页号,而 各级页表中记录的全是物理页号,指向下级页表 或真正的被访问页。
页表机制带来的问题
页表机制带来的严重问题就是内存访问效率的严重下 降,以二级分页地址机制为例,由不分页时的1 次 ,上升到了3 次,这个问题必须解决。
具有快表的地址变换机构
- 快表又称联想存储器(Associative Memory) 、TLB (Translation Lookaside Buffer) 转换表查找缓冲 区,IBM最早采用TLB。
- 快表是一种特殊的高速缓冲存储器(Cache),内容 是页表中的一部分或全部内容。
- CPU 产生逻辑地址的页号,首先在快表中寻找,若命 中就找出其对应的物理块;若未命中,再到页表中找 其对应的物理块,并将相应的页表项复制到快表。若 快表中内容满,则按某种算法淘汰某些页。
- 通常,TLB中的条目数并不多,在64~1024之间。
- 支持页式管理的硬件部件通常称为MMU(Memory Management Unit)。
快表(TLB)
TLB的性质和使用方法与Cache相同:
- TLB只包括页表中的一小部分条目。当CPU产生逻辑地 址后,其页号提交给TLB。如果不在TLB中(称为TLB 失效),那么就需要访问页表,并将页号和帧号增加 到TLB中。
- 如果TLB中的条目已满,那么操作系统会选择一个来 替换。替换策略有很多,从最近最少使用替换(LRU )到随机替换等。
- 另外,有的TLB允许有些条目固定下来。通常内核代码的条目是固定下来的。
TLB的其它特性
- 有的TLB在每个TLB条目中还保存地址空间标识码( address-space identifier,ASID)。ASID可用来唯 一标识进程,并为进程提供地址空间保护。当TLB试 图解析虚拟页号时,它确保当前运行进程的ASID与虚 拟页相关的ASID相匹配。如果不匹配,那么就作为 TLB失效。
- 除了提供地址空间保护外,ASID允许TLB同时包含多 个进程的条目。如果TLB不支持独立的ASID,每次选 择一个页表时(例如,上下文切换时),TLB就必须 被冲刷(flushed)或删除,以确保下一个进程不会 使用错误的地址转换。
有效内存访问时间EAT(一级页表)
-
EAT-Effective Access Time
-
TLB查询时间= ε 时间单位
-
单次内存访问时间= τ 时间单位
-
TLB的命中率是α
-
EAT的计算:
哈希页表(hashed page table)
- 处理超过32位地址空间的一种常用方法是使用哈希页 表(hashed page table),根据虚拟页号的哈希值 来访问页表。哈希页表的每一表项都包括一个链表的 元素,这些元素哈希成同一位置(要处理碰撞)。每 个元素有3个域:
- 虚拟页号
- 所映射的页框号
- 指向链表中下一个元素的指针。
- 具体过程:将虚拟页号转换为哈希值,据此访问哈 希表的表项(链表)。用虚拟页号与链表中的元素 的第一个域相比较。如果匹配,那么相应的页框号 (第二个域)就用来形成物理地址;如果不匹配, 那么就进一步比较链表的下一个节点,以找到匹配 的页号。
反置页表(Inverted page table)
- 每个进程都有一个相关页表,该进程所使用的每个页 都在页表中有一项。这种页的表示方式比较自然,这 是因为进程是通过页的虚拟地址来引用页的。操作系 统必须将这种引用转换成物理内存地址。
- 这种方法的缺点之一是每个页表可能有很多项。这些 表可能消耗大量物理内存,却仅用来跟踪物理内存是 如何使用的。对于每个使用32位逻辑地址的进程, 其 页表长度均为4MB。
- 为了解决这个问题,可以使用反向页表(inverted page table)。
- 反置页表不是依据进程的逻辑页号 来组织,而是依据该进程在内存中 的页框号来组织(即:按页框号排 列),其表项的内容是逻辑页号P 及隶属进程标志符pid。
- 反置页表的大小只与物理内存的大 小相关,与逻辑空间大小和进程数 无关。如: 64M主存,若页面大小为 4K,则反向页表只需64KB。
- 如64位的PowerPC, UltraSparc等 处理器。
利用反置页表进行地址变换:
- 用进程标志符和页号去检索反置页表。
- 如果检索完整个页表未找到与之匹配的页表项,表明此页 此时尚未调入内存,对于具有请求调页功能的存储器系统 产生请求调页中断,若无此功能则表示地址出错。
- 如果检索到与之匹配的表项,则表项的序号i 便是该页 的物理块号,将该块号与页内地址一起构成物理地址。
- 反置页表按照物理地址排序,而查找依据虚拟地址,所以 可能需要查找整个表来寻找匹配。
- 可以使用哈希页表限制页表条目或加入TLB 来改善。
- 通过哈希表(hash table)查找可由逻辑页号得到物理页面 号。虚拟地址中的逻辑页号通过哈希表指向反置页表中的 表项链头(因为哈希表可能指向多个表项),得到物理页 面号。
- 采用反置页表的系统很难共享内存,因为每个物理帧只对 应一个虚拟页条目。
页共享与保护
各进程把需共享的数据/代码的相应页面指向相同页 框。
页的保护
- 页式存储管理系统提供了两种方式:
- 地址越界保护
- 在页表中设置保护位(定义操作权限:只读,读写,执行等)
共享带来的问题
- 若共享数据与不共享数据划在同一页框中,则:
- 有些不共享的数据也被共享,不易保密。
- 实现数据共享的最好方法:分段存储管理。
三、段式内存管理
段式存储管理的主要动机
信息保护:
- 页式管理中,一个页面中可能装有2 个不同的子程序 段的指令代码,不能通过页面共享实现一个逻辑上完整 的子程序或数据块的共享。
- 段式管理中,可以使用信息的逻辑单位进行保护。
动态增长:
- 实际应用中,某些段(数据段)会不断增长,前面的存 储管理方法均难以实现。
动态链接:
- 动态链接在程序运行时才把主程序和要用到的目标程序 (程序段)链接起来。
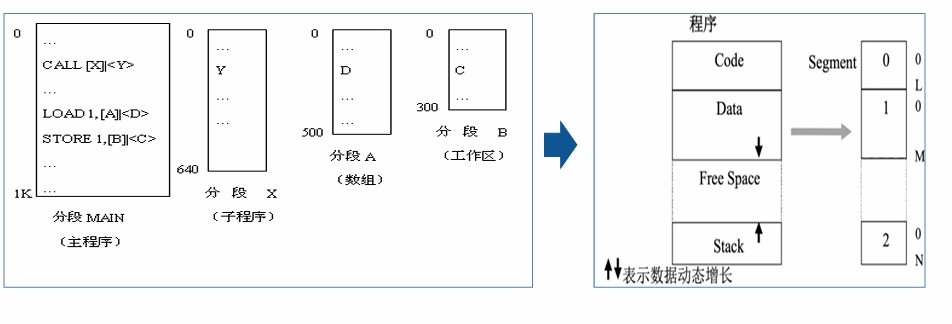
基本思想:分段地址空间
- 一个段可定义为一组逻辑信息,每个作业的地址空间 是由一些分段构成的(由用户根据逻辑信息的相对完 整来划分),每段都有自己的名字(通常是段号), 且都是一段连续的地址空间,首地址为0。
地址变换
段表
-
段表记录了段与内存位置的对应关系。
-
段表保存在内存中。
-
段表的基址及长度由段表寄存器给出。
段表始址 段表长度 -
访问一个字节的数据/指令需访问内存两次(段表一 次,内存一次)。
-
逻辑地址由段和段内地址组成。
段号 段内地址
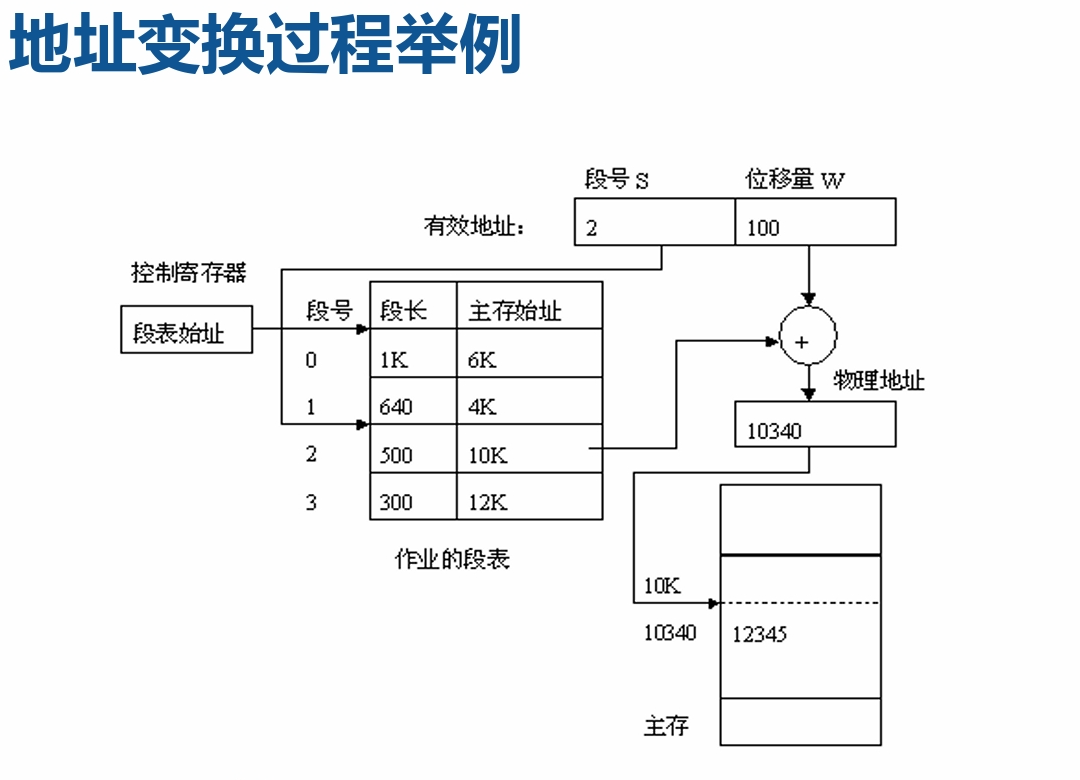
地址变换过程
- 将逻辑地址中的段号S 与段表长度TL 进行比较。
- 若S>TL,表示访问越界,产生越界中断。
- 若未越界,则根据段表的始址和该段的段号,计算出该 段对应段表项的位置,从中读出该段在内存的始址。
- 再检查段内地址d,是否 超过该段的段长SL。
- 若超过,即d >SL,同样 发出越界中断信号。
- 若未越界,则将该段的基 址与段内地址d 相加, 即可得到要访问的内存物 理地址。
信息共享(分段与分页比较)
例:一个系统可同时接纳40个用户,都执行一个文本编 辑程序。程序有160KB代码和40KB数据区,如果不共享 ,则共需8MB内存。可采用共享代码,在内存中只需保 留一份代码副本,则所需内存仅为1760 KB
要求:代码是可重入的
补充知识:可重入代码
可重入代码(Reentrant Code) 又称为“纯代码” (Pure Code),是指在多次并发调用时能够安全运行 的代码。
要求:不能使用全局/静态变量;代码不能 修改代码本身;不能调用其他的不可重入代码。
分段管理的优缺点
- 优点:
- 分段系统易于实现段的共享,对段的保护也十分简单。
- 更好地支持动态的内存需求
- 缺点:
- 处理机要为地址变换花费时间;要为段表提供附加的存 储空间。
- 为满足分段的动态增长和减少外碎片,要采用内存紧凑 的技术手段。
- 在辅存中管理不定长度的分段比较困难(交换)。
- 分段的最大尺寸受到主存可用空间的限制。
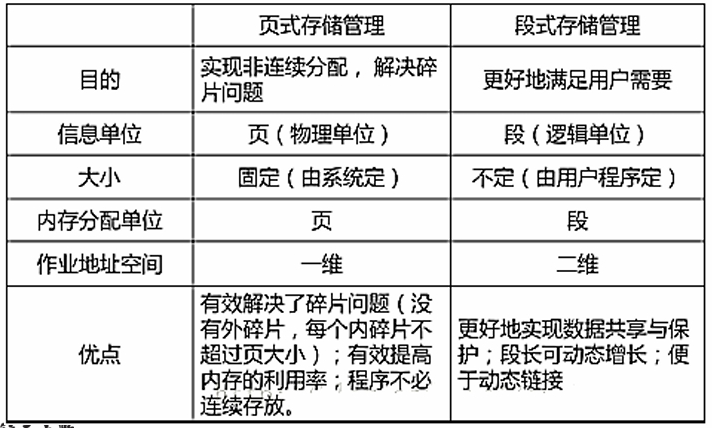
分页与分段的比较
-
分页的作业的地址空间是单一的线性地址空间(注:页式 管理所用的一维的虚拟地址也称为线性地址),分段作业的地址空间是二维的。
分页是一维的:地址映射可以根据页面大小判断出哪部分是页内地址,哪部分是页表中的页号,然后执行。
分段是二维的:需要段号和段内地址才能映射到物理地址。
-
“页”是信息的“物理”单位,大小固定。“段”是信 息的逻辑单位,即它是一组有意义的信息,其长度不定。
-
分页对用户是透明 的,是系统对于主 存的管理。分段是 用户可见的(分段 可以在用户编程时 确定,也可以在编 译程序对源程序编 译时根据信息的性 质来划分)
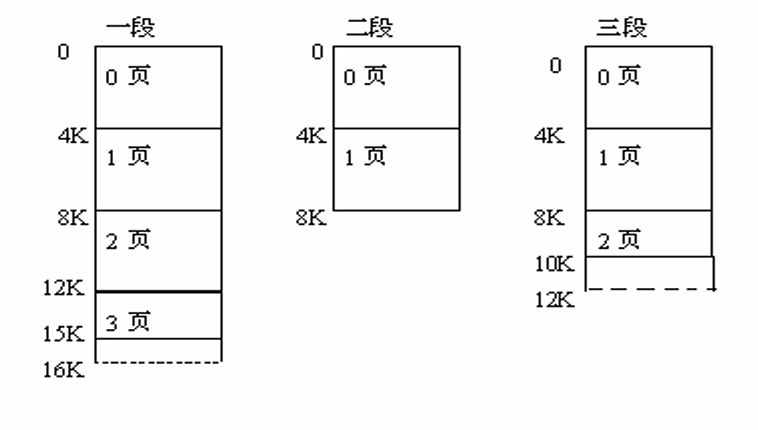
段页式存储管理:分段+分页
- 基本思想:用分段方法来分配和管理虚拟存储器,而 用分页方法来分配和管理实存储器。
实现原理
-
段页式存储管理:分段和分页原理的结合,即先将用户程 序分成若干个段(段式),并为每一个段赋一个段名, 再把每个段分成若干个页(页式)。
-
地址结构由段号、段内页号、及页内位移三部分所组成。
段号(S) 段内页号(P) 页内地址(W) -
系统中设段表和页表,均存放于内存中。读一次指令或数 据须访问内存三次。为提高速度可增设高速缓存。
-
每个进程一张段表,每个段一张页表。
-
段表含段号、页表始址和页表长度;页表包含页号和页框 号。
段页式存储管理的地址变换
- 从PCB 中取出段表始址及段表长度,装入段表寄存 器
- 将段号与段表长度进行比较,若段号大于或等于段表 长度,产生越界中断。
- 利用段表始址与段号得到该段表项在段表中的位置。 取出该段的页表始址和页表长度。
- 将页号与页表长度进行比 较,若页号大于或等于页 表长度,产生越界中断。
- 利用页表始址与页号得到该页 表项在页表中的位置。
- 取出该页的物理块号,与页内 地址拼接得到物理地址。
四、虚拟内存管理
常规存储管理的问题
常规存储管理方式的特征:
- 一次性:要求一个作业全部装入内存后方能运行。
- 驻留性:作业装入内存后一直驻留内存,直至结束。
可能出现的问题:
- 有的作业很大,所需内存空间大于内存总容量,使作业 无法运行。
- 有大量作业要求运行,但内存容量不足以容纳下所有作 业,只能让一部分先运行,其它在外存等待。
已有解决方法:
- 增加内存容量
- 从逻辑上扩充内存容量:覆盖、对换
程序的局部性
- 程序在执行时,大部分是顺序执行的指令,少部分是 转移和过程调用指令。(空间局部性)
- 过程调用的嵌套深度有限,因此执行的范围不超过这 组嵌套的过程。(空间局部性)
- 程序中存在很多对特定数据结构的操作,如数组操作 ,往往局限在较小范围内。(空间局部性)
- 程序中存在很多循环结构,它们由少量指令组成,而 被多次执行。(时间局部性)
局部性原理
指程序在执行过程中的一段较短时间内,所执行的指 令地址和指令的操作数地址分别局限于一定区域。具 体表现为:
- 时间局部性:即一条指令的一次执行和下次执行,一个 数据的一次访问和下次访问都集中在一段较短时间内;
- 空间局部性:即当前指令和邻近的几条指令,当前访问 的数据和邻近的数据都集中在一个较小区域内。
虚拟内存
虚拟内存是计算机系统存储管理的一种技术。它为 每个进程提供了一个大的、一致的、连续可用的和 私有的地址空间(一个连续完整的地址空间)。
虚拟存储提供了3个能力:
- 给所有进程提供一致的地址空间,每个进程都认为自 己是在独占使用单机系统的存储资源;
- 保护每个进程的地址空间不被其他进程破坏,隔离了 进程的地址访问;
- 根据缓存原理,上层存储是下层存储的缓存,虚拟内 存把主存作为磁盘的高速缓存,在主存和磁盘之间根 据需要来回传送数据,高效地使用了主存;
虚拟存储管理的目标
- 借鉴覆盖技术:不必把程序的所有内容都放在内存中,因 而能够运行比当前的空闲内存空间还要大的程序。
- 与覆盖不同:由操作系统自动完成,对程序员是透明的。
- 借鉴交换技术:能够实现进程在内存与外存之间的交换, 因而获得更多的空闲内存空间。
- 与交换不同:只将进程的部分内容(更小的粒度,如分页) 在内存和外存之间进行交换。
虚拟存储的基本原理
- 在程序装入时,不需要将其全部读入到内存,而只需 将当前需要执行的部分页或段读入到内存,就可让程 序开始执行。
- 在程序执行中,如果需执行的指令或访问的数据尚未 在内存(称为缺页或缺段),则由处理器通知操作 系统将相应的页或段调入到内存,然后继续执行程序 。(请求调入功能)
- 操作系统将内存中暂时不使用的页或段调出保存在外 存上,从而腾出空间存放将要装入的程序以及将要调 入的页或段。(置换功能)
虚拟存储技术的特征
-
离散性:物理内存分配的不连续,虚拟地址空间使用的不 连续(数据段和栈段之间的空闲空间,共享段和动态链接 库占用的空间)
-
多次性:作业被分成多次调入内存运行。正是由于多次性 ,虚拟存储器才具备了逻辑上扩大内存的功能。多次性是虚拟存储器最重要的特征,其它任何存储器不具备这个特 征。
-
对换性:允许在作业运行过程中进行换进、换出。换进、 换出可提高内存利用率。
-
虚拟性:允许程序从逻辑的角度访问存储器,而 不考虑物理内存上可用的空间容量。
- 范围大,但占用容量不超过物理内存和外存交换区容量 之和。
- 占用容量包括:进程地址空间中的各个段,操作系统代 码。
虚拟性以多次性和对换性为基础, 多次性和对换性必须以离散分配为基础。
优点、代价和限制
优点:
- 可在较小的可用(物理)内存中执行较大的用户程序;
- 可在(物理)内存中容纳更多程序并发执行;
- 不必影响编程时的程序结构(与覆盖技术比较)
- 提供给用户可用的虚拟内存空间通常大于物理内存
代价:
- 虚拟存储量的扩大是以牺牲CPU 处理时间以及内外 存交换时间为代价。
限制:
- 虚拟内存的最大容量主要由计算机的地址结构决定 。例如: 32 位机器的虚拟存储器的最大容量就是4GB。
与Cache-主存机制的异同
相同点:
- 出发点相同:二者都是为了提高存储系统的性能价格比 而构造的分层存储体系,都力图使存储系统的性能接近 高速存储器,而价格和容量接近低速存储器。
- 原理相同:都是利用了程序运行时的局部性原理把最近 常用的信息块从相对慢速而大容量的存储器调入相对高 速而小容量的存储器。
不同点:
- 侧重点不同:cache主要解决主存与CPU的速度 差异问题;虚存主要解决存储容量问题,另外 还包括存储管理、主存分配和存储保护等。
- 数据通路不同:CPU与cache和主存之间均有直 接访问通路,cache不命中时可直接访问主存 ;而虚存所依赖的辅存与CPU之间不存在直接 的数据通路,当主存不命中时只能通过调页解 决,CPU最终还是要访问主存。
- 透明性不同:cache的管理完全由硬件完成, 对系统程序员和应用程序员均透明;而虚存管 理由软件(OS)和硬件共同完成,由于软件的 介入,虚存对实现存储管理的系统程序员不透 明,而只对应用程序员透明(段式和段页式管 理对应用程序员“半透明”)。
- 未命中时的损失不同:由于主存的存取时间是 cache的存取时间的5~10倍,而主存的存取速 度通常比辅存的存取速度快上千倍,故主存未 命中时系统的性能损失要远大于cache未命中 时的损失。
实存(物理内存)管理与虚存管理
实存管理:
- 分区(Partitioning)(连续分配方式)(包括固 定分区、可变分区)
- 分页(Paging)
- 分段(Segmentation)
- 段页式(Segmentation with paging)
虚存管理:
- 请求分页(Demand paging)– 主流技术
- 请求分段(Demand segmentation)
- 请求段页式(Demand SWP )
请求分页(段)系统
- 在分页(段)系统的基础上,增加了请求调页(段)功能、页 面(段)置换功能所形成的页(段)式虚拟存储器系统。
- 允许只装入若干页(段)的用户程序和数据,便可启动运行 ,以后在硬件支持下通过调页(段)功能和置换页(段)功能 ,陆续将要运行的页面(段)调入内存,同时把暂不运行的 页面(段)换到外存上,置换时以页面(段)为单位。
- 系统须提供相应的硬件和软件支持:
- 硬件支持:请求分页(段)的页(段)表机制、缺页(段) 中断机构和地址变换机构。
- 软件:请求调页(段)功能和页(段)置换功能的软件。
虚存机制要解决的关键问题
- 地址映射问题:进程空间到虚拟存储的映射问题;
- 调入问题:决定哪些程序和数据应被调入主存,以 及调入机制。
- 替换问题:决定哪些程序和数据应被调出主存。
- 更新问题:确保主存与辅存的一致性。
- 其它问题:存储保护与程序重定位等问题
在操作系统的控制下,硬件和系统软件为用户 解决了上述问题,从而使应用程序的编程大大简化 。
请求分页式管理
基本概念
- 进程的逻辑空间(虚拟地址空间) 一个进程的逻辑空间的建立是通过链接器(Linker),将构成 进程所需要的所有程序及运行所需环境,按照某种规则装配 链接而形成的一种规范格式(布局),这种格式按字节从0开始 编址所形成的空间也称为该进程的逻辑地址空间。由于该逻 辑空间并不是物理上真实存在的,所以也称为进程的虚拟地 址空间。
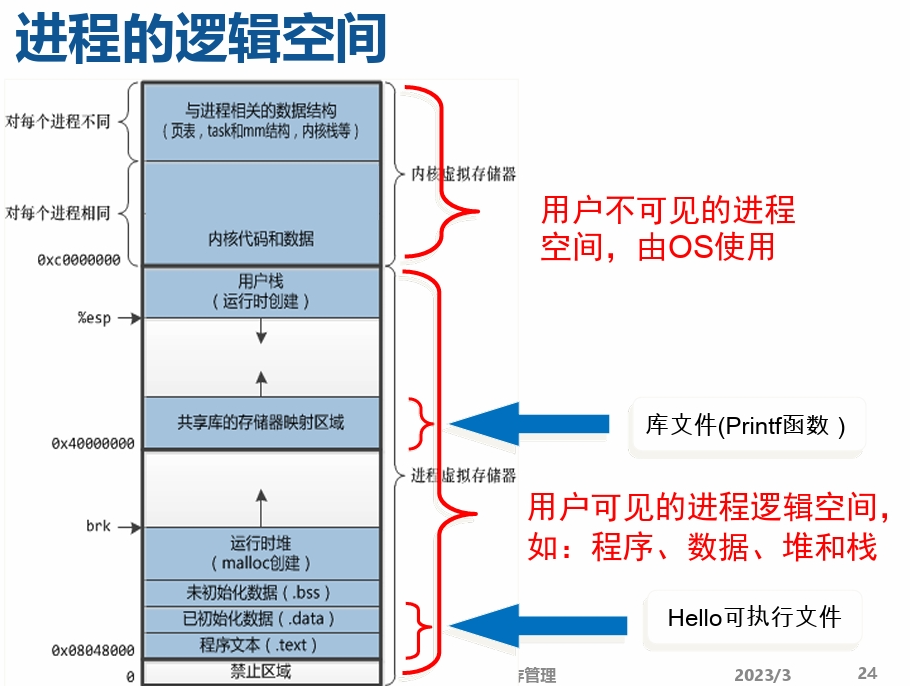
- 虚拟地址空间和虚拟存储空间
- 进程的虚拟地址空间即为进程在内存中存放的逻辑视 图。因此,一个进程的虚拟地址空间的大小与该进 程的虚拟存储空间的大小相同,都从0开始编址。
- 交换分区(交换文件)
- 一段连续的磁盘空间(按页划分的),并且对用户不可 见。它的功能就是在物理内存不够的情况下,操作系统 先把内存中暂时不用的数据,存到硬盘的交换空间,腾 出物理内存来让别的程序运行。
- 在Linux系统中,交换分区为swap;在Windows系统中 则以文件的形式存在(pagefile.sys)。
- 交换分区的大小:交换分区的大小应当与系统物理内存 (M)的大小保持线性比例关系(Linux中):
If (M < 2GB) swap = 2*M else swap = M+2GB
地址映射问题
进程空间到虚存空间的映射(进程的虚存分配)
- 在程序装入时,由装载器(Loader)完成。
- 分配是以段为单位(需页对齐)进行的。
- 事实上,在每个进程创建加载时,内核只是为进程 “创建”了虚拟内存的布局,同时建立好虚拟内存 和磁盘文件之间的映射(即存储器映射)。实际 上,并不立即就把虚拟内存对应位置的程序数据和 代码(比如.text .data段)拷贝到物理内存中, 等到运行对应的程序时,才会通过缺页异常,来拷 贝数据。
- 用户可执行文件(如Hello World可执行文件)及 共享库(如HelloWorld中调用的库文件中的printf 函数)都是以文件的形式存储在磁盘中,初始时其 在页表中的类型为file backed,地址为相应文件 的位置。
- 堆(heap)和栈(stack)在磁盘上没有对应的 文件,页表中的类型为anonymous,地址为空。
- 未分配部分没有对应的页表项,只有在申请时 (如使用malloc( )申请内存或用mmap( )将文 件映射到用户空间)才建立相应的页表项。

调入问题
哪些程序和数据调入主存,何时调入,如何调入?
- 哪些程序和数据调入主存?
- OS核心部分的程序和数据;
- 正在运行的用户进程相关的程序及数据。
- 何时调入?
- OS在系统启动时调入。
- 用户程序的调入取决于调入策略。常用的调度策有:
- 预调页:事先调入页面的策略。
- 按需调页:仅当需要时才调入页面的策略。
- 如何调入?
- 缺页错误处理机制。
页面调入策略:按需调页
- 也称请求式调页(demand paging)
- 当且仅当需要某页时才将其调入内存的技术称为按需调 页,被虚拟内存系统采用。
- 按需调页系统类似于使用交换的分页系统,进程驻留在外 存(磁盘),进程执行时使用懒惰交换(lazy swapper) 换入内存。一次装入请求的一个页面,磁盘I/O的启动频 率较高,系统的开销较大。
- 按需调页需要使用外存,保存不在内存中的页,通常为快 速磁盘,用于和内存交换页的部分空间称为交换空间( swap space)。
页面调入策略:预调页
- 当进程开始时,所有页都在磁盘上,每个页都需要通 过页错误(Page Fault,也称缺页异常)来调入内存 。预调页同时将所需要的所有页一起调入内存,从而 阻止了大量的页错误。部分操作系统如Solaris 对 小文件就采取预调页调度。
- 实际应用中,可以为每个进程维护一个当前工作集合 (working set,简称工作集)中的页的列表,如果 进程在暂停之后需要重启时,根据这个列表使用预调 页将所有工作集合中的页一次性调入内存。
- 若程序执行的局部性较差,则预先装入的很多页面不 会很快被引用,并会占用大量的内存空间,反而降低 系统的效率。
缺页错误处理过程
当进程执行中需访问的页面不在物理内存中时,会引发 发生缺页中断(也称缺页异常),进行所需页面换入, 步骤如下:
- 陷入内核态,保存必要的信息(OS及用户进程状态相 关的信息)。(现场保护)
- 查找出发生缺页中断的虚拟页面(进程地址空间中的 页面)。这个虚拟页面的信息通常会保存在一个硬件 寄存器中,如果没有的话,操作系统必须检索程序计 数器,取出这条指令,用软件分析该指令,通过分析 找出发生页面中断的虚拟页面。(页面定位)
- 检查虚拟地址的有效性及安全保护位。如果发生保护 错误,则杀死该进程。(权限检查)
- 查找一个空闲的页框(物理内存中的页面),如果没有 空闲页框则需要通过页面置换算法找到一个需要换出 的页框。(新页面调入1)
- 如果找的页框中的内容被修改了,则需要将修改的内 容保存到磁盘上¹。(注:此时需要将页框置为忙状态 ,以防页框被其它进程抢占掉)(旧页面写回)
- 页框“干净”后,操作系统将保持在磁盘上的页面内 容复制到该页框中²。(新页面调入2)
- 当磁盘中的页面内容全部装入页框后,向CPU发送一 个中断。操作系统更新内存中的页表项,将虚拟页面 映射的页框号更新为写入的页框,并将页框标记为正 常状态。(更新页表)
- 恢复缺页中断发生前的状态,将程序指针重新指向引 起缺页中断的指令。(恢复现场)
- 程序重新执行引发缺页中断的指令,进行存储访问。 (继续执行)
缺页处理过程涉及了用户态和内核态之间的切换,虚 拟地址和物理地址之间的转换(这个转换过程需要使 用MMU和TLB)
替换问题
- 当物理内存已满,而新的页面(位于Swap区或磁 盘上其它文件中)又必须调入时,必须选择适当 的页面(Victim Page)换出。如何选择?——答 案很简单,将造成系统运行损失最小(代价最小 )的页面换出。
- 系统代价
- 页面换入换出的开销
- 选择替换页面的过程复杂。如果选择不当,被换出 的页面很快又被换入,增加开销
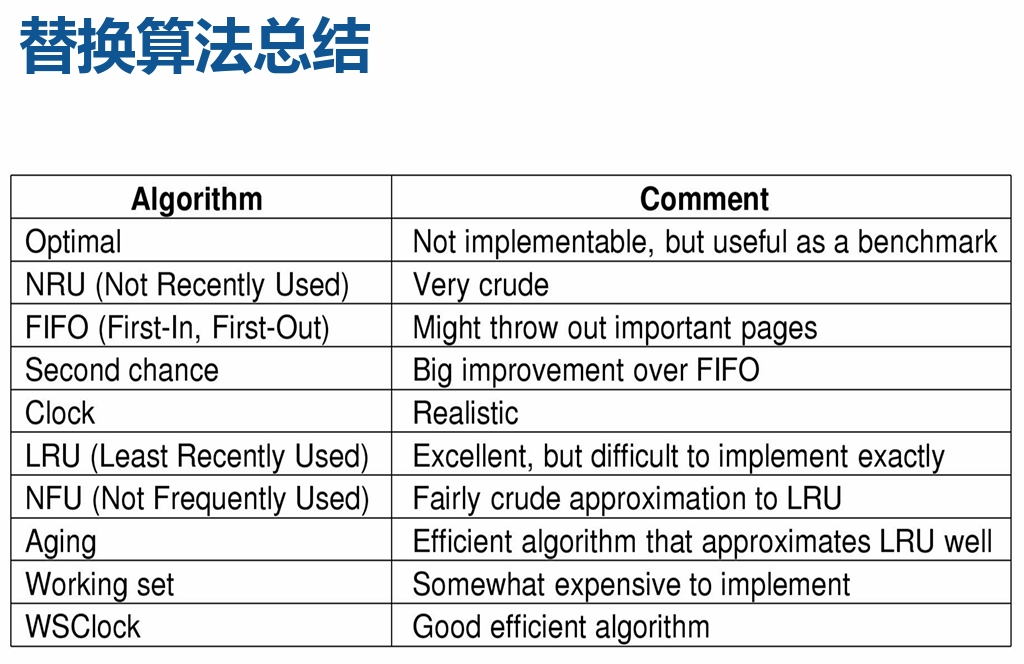
页面置换策略
- 最优置换(Optimal):从主存中移出永远不再需要的页 面,如这样的页面不存在,则应选择最长时间不需要访问 的页面。
- 先进先出(First-in, First-out):总选择作业中在主存 驻留时间最长的一页淘汰。
- 最近最少使用(Least Recently Used Replacement):当 需要置换一页面时,选择在最近一段时间内最久不用的页 面予以淘汰。
最优置换(OPT算法)
- 所有页置换算法中页错误率最低,但它需要引用 串(即页面访问序列)的先验知识,因此无法实 现。
- 算法将内存中的页P置换掉,页P满足:从现在开 始到未来某刻再次需要页P,这段时间最长。也就 是OPT 算法会置换掉未来最久不被使用的页。
- OPT 算法通常用于比较性研究,衡量其他页置换 算法的效果。
先进先出(First-in, First-out)
- 最简单的页置换算法,系统记录每 个页被调入内存的时间,当必需置 换掉某页时,选择最旧的页换出。 具体实现如下:
- 新访问的页面插入FIFO队列尾部, 页面在FIFO队列中顺序移动;
- 淘汰FIFO队列头部的页面;
- 性能较差。较早调入的页往往是经 常被访问的页,这些页在FIFO算法 下被反复调入和调出。可能出现 Belady异常现象。
Belady异常现象
- 在使用FIFO算法作为缺页置换算法时,随着分配的页框增 多,缺页率反而提高,这样的异常现象称为Belady’s Anomaly。
- 注意:虽然这种现象说明的场景是缺页置换,但在运用 FIFO算法作为缓存替换算法时,同样也会遇到,即增加缓 存容量,但缓存命中率反而会下降的情况。
改进的FIFO算法—Second Chance
其思想是“如果被淘汰的数据之前被访问过,则给其第 二次机会(Second Chance)”实现:
- 每个页面会增加一个访问标志位,用于标识此数据装入内存后是否 被再次访问过。
- A是FIFO队列中最旧的页面,且其放入队列后没有被再次访问,则A 被立刻淘汰;否则,如果放入队列后被访问过,则将A移到FIFO队 列尾部,并且将访问标志位清除。
- 如果所有页面都被访问过,则经过一次循环后就按FIFO原则淘汰。
改进的FIFO算法— Clock
-
Clock是Second Chance的改进版。通过一个环形队列,避免 将数据在FIFO队列中移动。算法如下:
-
如果没有缺页错误,将所访问页的访问位置1,指针不动;
-
如果产生缺页错误
(1)如果当前页面的访问位是1:首先将当前页面的访问位置0,将指针向 前移一个位置;重复这个过程,直到找到访问位为0的页面,然后转(2)。
(2)如果当前页面的访问位是0:则替换当前页面, 并将其访问位置为1, 并将指针向前移动一个位置。
-

最近最少使用LRU
- Least Recently Used,LRU算法根据数据的历史 访问记录来淘汰页面,其核心思想是“如果数据 最近被访问过,那么将来被访问的几率也更高” 。
- LRU是局部性原理的合理近似,性能接近OPT算法 。但需记录页面使用的先后关系,实现开销大。
- 一种软件的实现方法:链表法
- 设置一个链表,链表节点保存当前使用的页面的页号。
- 每当有一次内存访问(读/写),根据相应的页面号查找链表 ,如果找到,则把相应的节点移到链表头部;如果没有找到, 创建一个新的节点,插入到链表头部。
- 链表尾部为“最久未被使用”的页面,即淘汰的目标。
- 一种硬件的实现方法:计数器
- 设置指令计数器,每个页面在被访问时读取计数器,并记录相 应数值。淘汰计数值最小的页面。
- 一种软件的实现方法:链表法
LRU近似:老化算法(AGING)
LRU算法开销很大,硬件很难实现。老化算法是LRU算法 的一种近似,性能接近LRU:
- 为每个页面设置一个移位寄存器,每隔一段时间(clock tick),所有寄存器右移1位,并将访问位R值从左移入 。淘汰寄存器中数值最小的页面
工作集算法
- 工作集:进程运行正在使用的页面集合。
- 工作集的动态变化
- 进程开始执行后,随着不断访问新页面逐步建立较稳定的工 作集。
- 当内存访问的局部性区域的位置大致稳定时,工作集大小也 大致稳定;
- 局部性区域的位置改变时,工作集快速扩张和收缩过渡到下 一个稳定值。
- 工作集算法
- 给定一个进程,记录其工作集
- 当需要进行页面替换时,选择不 在工作集中的页面进行替换
获得精确工作集所面临的挑战:
- 准确记录工作集变化要求开销太大,例如:基于移位 寄存器的方式。
- 用过去一段时间内访问的页面集合进行近似
- 工作集:在[t - D, t]时间段内所访问的页面的集合,可 用一个二元函数W(t, D)表示;
- t是执行时刻,D是窗口尺寸;
- | W(t, D) | 指工作集大小即页面数目;
- 对工作集窗口大小的取值难以优化,而且通常该值是 不断变化的;
- 工作集的历史变化未必能够预示工作集将来的大小或 组成页面的变化;
更新问题
在虚存系统中,主存作为辅存(磁盘)的高速缓存,保 存了磁盘信息的副本。因此,当一个页面被换出时,为 了保持主辅存信息的一致性,必要时需要信息更新:
- 若换出页面是file backed类型,且未被修改,则直接 丢弃,因为磁盘上保存有相同的副本。
- 若换出页面是file backed的类型,但已被修改,则直 接写回原有位置。
- 若换出页面是anonymous类型,若是第一次换出或已被 修改,则写入swap区;若非第一次换出且未被修改,则 丢弃。
工作集与驻留集管理
前面我们从一个进程的角度,讨论了虚存管理中的相关 问题,下面我们将从系统管理者的角度(OS的视角)讨 论存在多个进程的情况下虚存管理的问题。
- 进程的工作集(working set):当前正在使用的页 面的集合。
- 进程的驻留集(Resident Set):虚拟存储系统中, 每个进程驻留在内存的页面集合,或进程分到的物理 页框集合。
- 引入工作集的目的是依据进程在过去的一段时间内访 问的页面来调整驻留集大小。
驻留集的管理
- 进程驻留集管理主要解决的问题:系统应当为每个活动进 程分配多少个页框。
- 影响页框分配的主要因素:
- 分配给每个活动进程的页框数越少,能够驻留内存的活动进 程数就越多,进程调度程序能调度就绪进程的概率就越大, 然而,这将导致进程发生缺页中断的概率较大;
- 为进程分配过多的页框,并发运行的进程数降低,影响系统 资源利用率。
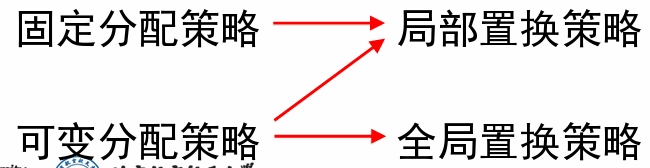
页面分配策略-固定分配策略
- 为每个活动进程分配固定数量的页框。即每个进程的 驻留集大小在运行期间固定不变。
- 为进程分配多少个页框是合理的呢?可以由系统根据 进程的类型确定,也可以由编程人员或系统管理员指 定。当进程执行过程中出现缺页时,只能从分给该进 程的内存块中进行页面置换。
页面分配策略-可变分配策略
- 为每个活动进程分配的页框数在其生命周期内是可变 的。即系统首先给进程分配一定数量的页框,运行期 间可以增/减页框。
- 可根据进程的缺页率调整进程的驻留集。当缺页率很 高时,驻留集太小,需增加页框;当缺页率一段时间 内都保持很低时,可以在不会明显增加进程缺页率的 前提下,回收其一部分页框,减小进程的驻留集。
- 可变分配策略比固定分配策略更灵活,既可以提高系 统的吞吐量,又能保证内存的有效利用。
- 可变分配要求统计进程的缺页率,增加系统额外开销 。而准确判断进程缺页率的高低,确定缺页率的阈值 是非常困难的。
- 可变分配策略不仅需要操作系统软件专门的支持,而 且,还需要处理机平台提供的硬件支持。
页面置换策略
- 当发生缺页中断且无足够的内存空间时,需要置换已 有的某些(个)页面。应该解决的基本问题:
- 当系统要把一个页面装入内存时,应当在什么范围内判 断已经没有空闲页框供分配?
- 当指定的范围内没有空闲页框时,应当从哪里选择哪个 页面移出内存?
- 局部置换策略:系统在进程自身的驻留集中判断当前 是否存在空闲页框,并在其中进行置换。
- 全局置换策略:在整个内存空间内判断有无空闲页框 ,并允许从其它进程的驻留集中选择一个页面换出内 存
分配模式与置换模式的搭配
- 全局置换的问题:程序无法控制缺页率。一个进程在 内存中的一组页面不仅取决于该进程的页面访问走向 ,也取决于其他进程的页面访问走向。因此,相同程 序由于外界环境不同会造成执行上的很大差别。
- 使用局部置换就不会出现这种情况,一个进程在内存 中的页面仅受本进程页面走向的影响。
- 可变分配策略+局部置换策略:可增加或减少分配给 每个活动进程的页框数;当进程的页框全部用完,而 需要装入一个新的页面时,系统将在该进程的当前驻 留集中选择一个页面换出内存。
内存块初始分配方法
- 等分法:为每个进程分配存储块的最简单的办法是平 分,即若有m块、n个进程,则每个进程分m/n块(其 值向下取整)。
- 比例法:分给进程的块数=(进程地址空间大小/全部 进程的总地址空间)*可用块总数
- 优先权法:为加速高优先级进程的执行,可以给高优 先级进程分较多内存。如使用比例分配法时,分给进 程的块数不仅取决于程序的相对大小,而且也取决于 优先级的高低。
抖动问题(thrashing)
- 随着驻留内存的进程数目增加,即进程并发程度的 提高,处理器利用率先上升,然后下降。
- 这里处理器利用率下降的原因通常称为虚拟存储器 发生“抖动”,也就是:每个进程的驻留集不断减 小,当驻留集小于工作集后,缺页率急剧上升,频繁调页使得调页开销增大。
- 因此,OS要选择一个 适当的进程数目,以 在并发水平和缺页率 之间达到一个平衡。
抖动的消除与预防
- 局部置换策略:如果一个进程出现抖动,它不能从另 外的进程那里夺取内存块,从而不会引发其他进程出 现抖动,使抖动局限于一个小的范围内。然而这种方 法并未消除抖动的发生。(微观层面)
- 引入工作集算法(微观)
- 预留部分页面(微观或宏观)
- 挂起若干进程:当出现CPU利用率、而磁盘I/O非常 频繁的情况时,就可能因为多道程序度太高而造成抖 动。为此,可挂起一个或几个进程,以便腾出内存空 间供抖动进程使用,从而消除抖动现象。(宏观)
负载控制
- 多道程序系统允许多个进程同时驻留内存,以提高系 统吞吐量和资源利用率。
- 如果同时驻留的进程数量太多,每个进程都竞争各自需 要的资源,反而会降低系统效率。将导致每个进程的驻 留集太小,发生缺页中断的概率很大,系统发生抖动的 可能性就会很大。
- 如果在内存中活动进程太少,则所有活动进程同时处于 阻塞状态的可能性就会很大,从而降低处理机利用率。
- 负载控制主要解决系统应当保持多少个活动进程驻留 在内存的问题,即控制多道程序系统的度。当内存中 的活动进程数太少时,负载控制将增加新进程或激活 一些挂起进程进入内存;反之,当内存中的进程数太 多时,负载控制将暂时挂起一些进程,减少内存中的 活动进程数。
系统负载的判断
L = S准则
- 通过调整多道程序的度,使发生两次缺页之间的平均时 间(L)等于处理一次缺页所需要的平均时间(S)。 即平均地,一次缺页处理完毕,再发生下一次缺页。此 时,处理机的利用率将达到最大。
50%准则
- 当分页单元的利用率保持在50%左右时,处理机的利用 率将达到最大。如果系统使用基于CLOCK置换算法的全 局置换策略,可通过监视扫描指针的移动速率来调整系 统负载。如果移动速率低于某个给定的阀值,则意味着 近期页面失败的次数较少,此时可以增加驻留内存的活 动进程数。如果超出阀值,则近期页面失败的次数较多 ,此时,系统应当减少驻留内存的活动进程数。
可挂起的进程
- 优先级最低的进程;
- 缺页进程:因为发生缺页中断的进程处于阻塞状态, 暂时不需要竞争处理机的使用权。而且,挂起一个缺 页进程时,挂起和激活操作需要的数据交换少,因而 将消除页替换的开销;
- 最后一个被激活的进程:因为为此类进程装入的页 面较少。将其挂起的开销较小;
- 驻留集最小的进程:将该类进程挂起以后,激活所需 的开销较小;
- 最大的进程:挂起最大的进程将获得最多的内存空间 ,可以满足内存中的进程申请空闲页框的需要,使它 们能尽快执行完成。
页面清除策略 ???
- 页面清除:将由置换算法选出的页面保存到外存。 页面清除策略决定系统何时把被置换页面写回外存。
- 若被选中的置换页面被修改过,则需要将该页面内容 写回外存,然后装入新页内容。可见,此时写出一个 页面与读入一个新页的操作是成对出现的,而且,写 出操作先于读入操作。所以,当正在执行的进程发生 缺页中断时,需要阻塞等待一个页面的写出和另一个 页面的读入,这可能降低处理机的使用效率。
- 一种有效的页面清除策略是结合页缓冲(Page Buffering)技术。当发生缺页中断时,不必首先写 出置换页,而是将被选中的置换页暂时保留在内存的 一个缓冲区,在以后某个合适的时候将被置换页批量 写出到外存。减少磁盘I/O的次数,提高处理机的效 率。
页面缓冲算法(page buffering)
- 该算法是对FIFO算法的发展,通过被置换页面的缓冲 ,有机会找回刚被置换的页面;
- 被置换页面的选择和处理:用FIFO算法选择被置换页 ,把被置换的页面放入两个链表之一。即:如果页面 未被修改,就将其归入到空闲页面链表的末尾,否则 将其归入到已修改页面链表。
改善时间性能的途径
- 降低缺页率:缺页率越低,虚拟存储器的平均访问时 间增加得越小;
- 提高外存的访问速度:外存和内存的访问时间比值越 大,则达到同样的时间延长比例,所要求的缺页率就 越低;反之,如果提高外存访问速度,则相同缺页率 下,系统时间性能会提高。
- 提高高速缓存命中率。
请求页式系统的性能
Effective Access Time (EAT)
写时复制技术
- 两个进程共享同一块物理内存,每个页面都被标志成 了写时复制。共享的物理内存中每个页面都是只读的 。如果某个进程想改变某个页面时,就会与只读标记 冲突,而系统在检测出页面是写时复制的,则会在内 存中复制一个页框,然后进行写操作。新复制的页框 对执行写操作的进程是私有的,对其他共享写时复制 页面的进程是不可见的。
- 写时复制的优点:
- 传统的fork()系统调用直接把所有的资源复制给新创 建的进程。这种实现过于简单而效率低下,因为它拷 贝的数据也许并不共享,如果新进程打算立即执行一 个新的映像,那么所有的拷贝都将前功尽弃。 §
- Linux的fork()使用写时复制(copy-on-write)实现, 它可以推迟甚至免除拷贝数据的技术。内核此时并不 复制整个进程地址空间,而是让父进程和子进程共享 同一个拷贝。只有在需要写入的时候,数据才会复制 ,从而使各个进程都拥有各自的拷贝。也就是说,资 源的复制只有在需要写入的时候才进行。
内存映射文件(Mem-Mapped File)
- 基本思想:进程通过一个系统调用(mmap)将一个文 件(或部分)映射到其虚拟地址空间的一部分,访问 这个文件就像访问内存中的一个大数组,而不是对文 件进行读写。
- 在多数实现中,在映射共享的页面时不会实际读入页 面的内容,而是在访问页面时,页面才会被每次一页 的读入,磁盘文件则被当作后备存储。
- 当进程退出或显式地解除文件映射时,所有被修改页 面会写回文件。
- 采用内存映射方式,可以方便地让多个进程共享一个 文件。
存储保护
- 界限保护(上下界界限地址寄存器):所有访问地址 必须在上下界之间;
- 用户态与内核态
- 存取控制检查
- 环保护:处理器状态分 为多个环(ring),分别 具有不同的存储访问特 权级别(privilege),通 常是级别高的在内环, 编号小(如0环)级别最 高;可访问同环或更低 级别环的数据;可调用 同环或更高级别环的服 务。
五、内存管理实例
Unix
Windows UT
难点:页目录自映射
